

DeepSeek-V3 is an incredibly powerful, free, and open-source AI model that outperforms some of the latest models from OpenAI and Meta on key benchmarks, all while being developed at a fraction of the cost.
Just a few days ago, OpenAI introduced its latest o3 models with a preview of some of its capabilities. The new model’s astounding benchmark results ignited the debate around the possibility of it being Artificial General Intelligence.
While this a giant leap in the progress of AI, another AI model has been making waves across the AI community.
Touted to be more capable of even the most advanced AI models, Chinese AI lab DeepSeek’s proprietary model DeepSeek-V3 has surpassed GPT-4o and Claude 3.5 Sonnet in various benchmarks.
The model stands for innovation, lower costs, and a future where cutting-edge AI is not confined to a handful of tech giants.
DeepSeek-V3 is hailed as the latest breakthrough in AI technology and highlights some high-tech innovations that aim to redefine AI applications.
One of the founding members of OpenAI, Andrej Karpathy, in his post on X, noted that DeepSeek-V3 was trained on a significantly smaller budget and fewer resources compared to other frontier models.
According to the former director of AI at Tesla, while leading models would usually require clusters of 16,000 GPUs and large computational resources, the Chinese lab achieved remarkable results with just 2,048 GPUs, trained for two months at as low as $6 million.
Here is a deep dive into what constitutes DeepSeek-V3 – its architecture, capabilities, pricing, benchmarks, and how it stands out among its peers.
What is DeepSeek-V3?
DeepSeek-V3 is a massive open-source AI model that has been trained on a budget of $5.5 million, quite contrary to the $100 million cost of training GPT-4o.
This is an AI model that can be categorised as Mixture-of-Experts (MoE) language model. In essence, MoE models are like a team of specialist models working together to answer a question.
In place of one big model handling everything, MoE has numerous ‘expert’ models, each trained to be good at specific tasks.
The model has 671 billion parameters, but reportedly only 37 billion are activated to process any given task. Experts say this selective activation lets the model deliver high performance without excessive computational resources.
DeepSeek-V3 is trained on 14.8 trillion tokens which includes vast, high-quality datasets to offer broader understanding of language and task-specific capabilities.
Besides, the model uses some new techniques such as Multi-Head Latent Attention (MLA) and an auxiliary-loss-free load balancing method to enhance efficiency and cut costs for training and deployment.
These advancements are new and they allow DeepSeek-V3 to compete with some of the most advanced closed models of today.
The model is built on NVIDIA H800 chips, a lower-performance but more cost-effective alternative to H100 chips that has been designed for restricted markets like China. Despite the limitations, the model delivers some stellar results.
With its innovative technology, DeepSeek-V3 is seen as a big leap in AI architecture and training efficiency. Reportedly, the model not only offers state-of-the-art performance, but accomplishes it with extraordinary efficiency and scalability.
Defining Features
As mentioned above, the DeepSeek-V3 uses MLA for optimal memory usage and inference performance.
Reportedly, MoE models are known for performance degradation, which DeepSeek-V3 has minimised with its auxiliary-loss-free load balancing feature.
These make the model a top choice for tasks that are computationally intensive. The entire process of training the model has been cost-effective with less memory usage and accelerated computation.
Moreover, DeepSeek-V3 can process up to 128,000 tokens in a single context, and this long-context understanding gives it a competitive edge in areas like legal document review and academic research.
The model also features multi-token prediction (MTP), which allows it to predict several words at the same time, thereby increasing speed by up to 1.8x tokens per second. It needs to be noted that traditional models predict one word at a time.
Perhaps one of the biggest advantages of DeepSeek-V3 is its open-source nature. The model provides researchers, developers, and companies with unrestricted access to its capabilities.
In essence, this allows smaller players to access high-performance AI tools and allows them to compete with bigger peers.
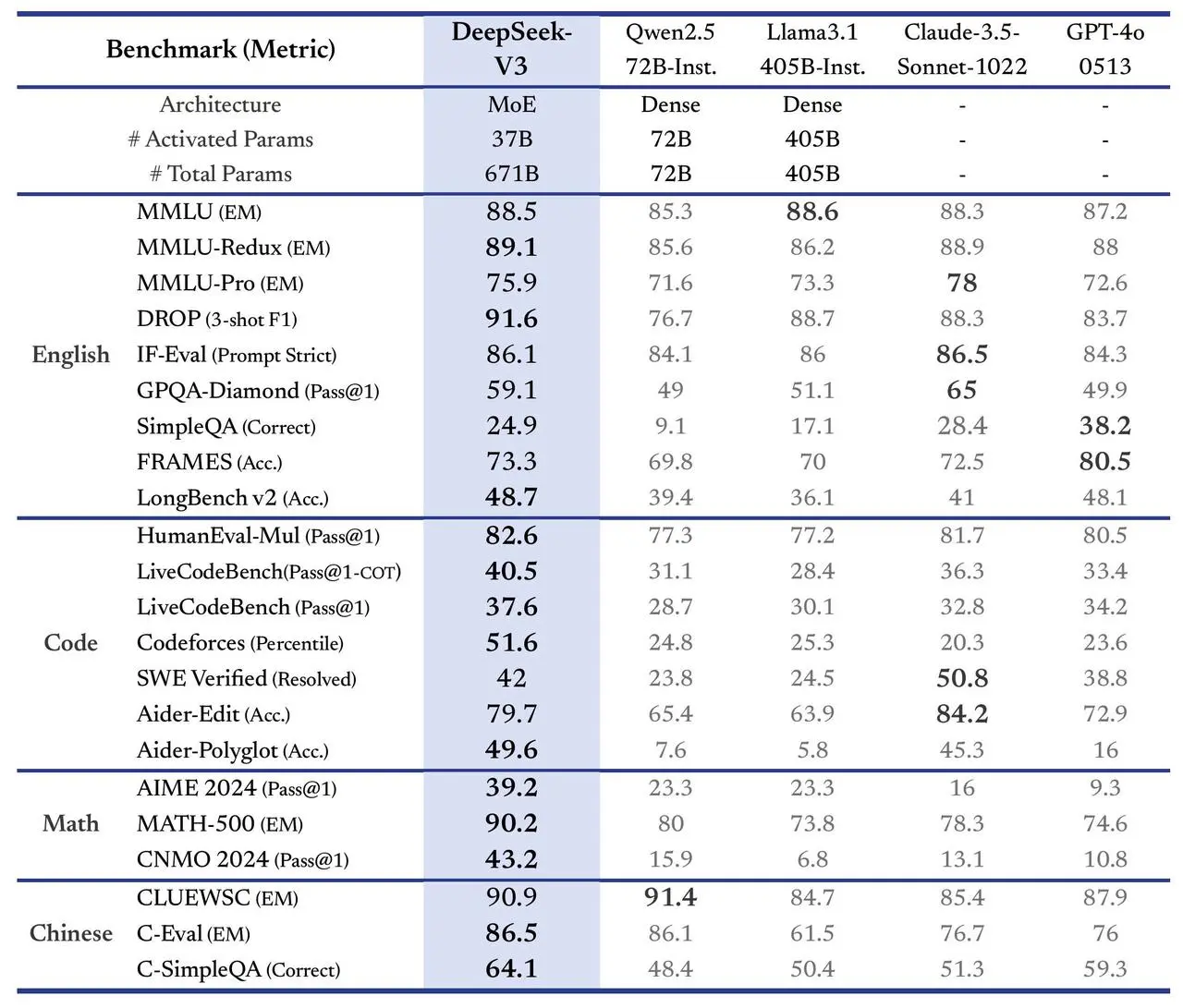
Performance
When it comes to performance, DeepSeek has compared the model with its peers, such as Claude-3.5, GPT-4o, Qwen2.5, Llama3.1, etc., and it performs exceptionally across benchmarks.
The DeepSeek-V3 competes directly with established closed-source models like OpenAI’s GPT-4o and Anthropic’s Claude 3.5 Sonnet and surpasses them in several key areas.
When it comes to mathematics and coding, the model outperformed its competitors in benchmarks like MATH-500 and LiveCodeBench.
This shows the model’s superior problem-solving and programming abilities. Besides, the model also excels in tasks that require an understanding of lengthy texts.
In Chinese language tasks, the model demonstrated exceptional strength.
When it comes to limitations, the DeepSeek-V3 may need significant computational resources.
Although it is faster than its previous version, the model’s real-time inference capabilities reportedly need further optimisation.
Some users also argued that its focus on excelling in Chinese-language tasks has impacted its performance in English factual benchmarks.
The Bigger Picture
The US and China have been spearheading the AI arms race. US export controls have restricted China’s access to advanced NVIDIA AI chips, with an aim to contain its AI progress.
Now, with DeepSeek-V3’s innovation, the restrictions may not have been as effective as it was intended. The model is fully open-source, and it also raises questions about the safety and consequences of releasing powerful AI models to the public.
The new model is also signalling a paradigm shift, as now powerful AI models can be trained without exorbitant investments. This also shows how open-source AI may continue to challenge closed model developers like OpenAI and Anthropic.
The DeepSeek-V3 model is freely available for developers, researchers, and businesses. It can be accessed via GitHub.
Recently, TechEnthu published that OpenAI unveiled its latest advancements in artificial intelligence (AI) with the announcement of the o3 model and its counterpart, o3 Mini.
